Working with images Diving into the cool stuff
Table of Contents:
Over the past three weeks, we’ve gotten really solid at the fundamentals of machine learning, gone over backpropagation and gradient optimization algorithms and looked at sequence and textual data. This week, we’ll dive into dealing with visual data and explore a class of neural network architectures called Convolutional Neural Networks.
CNN Overview
CNNs are a class of neural networks that operate on visual data. They are preferred to fully connected (dense) layers because of their ability to capture spatial information, downsample an image to find increasingly granular patterns and do it all more efficiently than a fully connected layer would.
Unlike an FC layer, CNNs don’t require flattening of the input image and instead rely on the concept of a receptive field. A receptive field(aka kernel, filter) goes through different parts of the image successively and performs a matrix computation which leads to one output for each location in the image. Represented as a 2D matrix, a receptive field is composed of weight parameters which are element wise multiplied with the pixel values in the image.
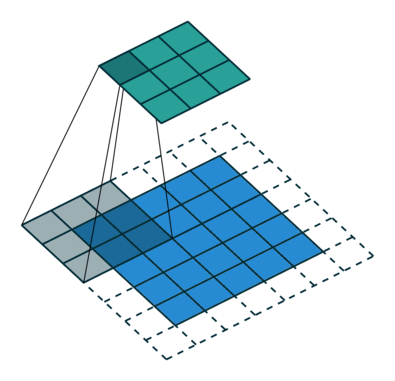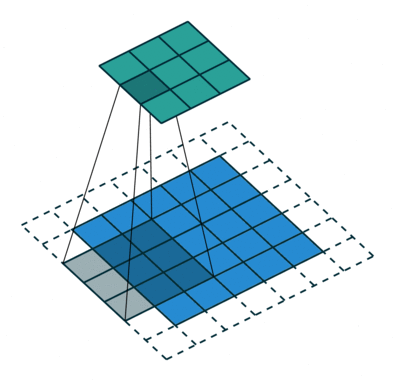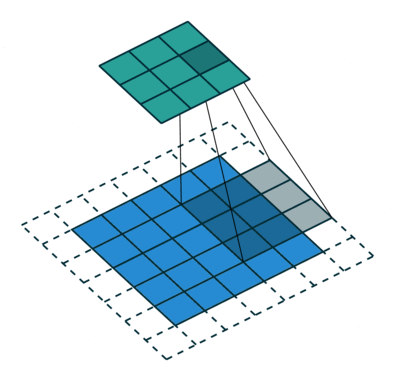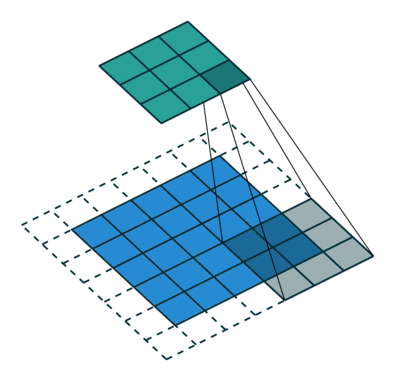
NOTE: Image Credits: Deep Dive into Convolutional Neural Networks
The receptive field convolves over the image input, across its receptive field and does an element-wise multiplication. It then moves (slides) to a different part of the image and does the same computation again, till the image has been processed completely. This leads to a feature map(aka activation map) for the image, which represents the activated output for the given image. Depending on the depth of the network, different layers will recognize different kinds of features and the deeper you go, the more fine it gets.
CNN Concepts
Padding and Stride are two parameters that allow us to manipulate how a filter convolves over the input.
Stride
Stride represents the shift that each filters makes over sucessive iterations on the input, allowing it to capture spatial information around the pixel it is currently looking at.
Padding
Padding will pad the border of the input ie. zero padding pads zeros around the border of the image. Padding is relevant here because it ensures that the successive layers in the network are able to operate on the input volume, rather than decreasing inputs which are a result of the convolution operation.
Two types of padding:
- Full: Zero pads the input such that all pixels are visited exactly the same number of times.
- Same: Pads the input such that the output feature map has the same size as the input feature map
Pooling
Pooling layers are an important part of any CNN architecture and are used for downsampling an image. They are used to reduce the dimensions of the width and height dimensions. This reduces the number of parameters that the next layer operates on, reducing training time. However, the biggest advantage to pooling is rotatiaonal invariance ie. it reduces overfitting.
https://blog.xrds.acm.org/2016/06/convolutional-neural-networks-cnns-illustrated-explanation/
The image below is an example of max-pool

NOTE: Image Credits: Convolutional Neural Networks: An Illustrated Explanation
A Typical CNN Architecture
A typical CNN architecture consists of many of the concepts we’ve talked about today and over the last 2 weeks. The convolutional layer is always the first layer in a CNN, operating on the input with a given receptive field and stride and padding. This leads to activation maps, which are then passed through an activation function(ReLU). This is generally followed by a pooling layer(max-pool). This chain of layers constitutes one block in a CNN.
There can be many number of blocks. The last CNN block is connected to a Fully Connected layer with an arbitrary number of inputs. However, the last FC layer will have as many neurons as the number of target variables.
For classification, this last FC layer is attached to a softmax classifier which looks at the final output and assigns a class variable to the input.
A typical CNN architecture looks as follows:
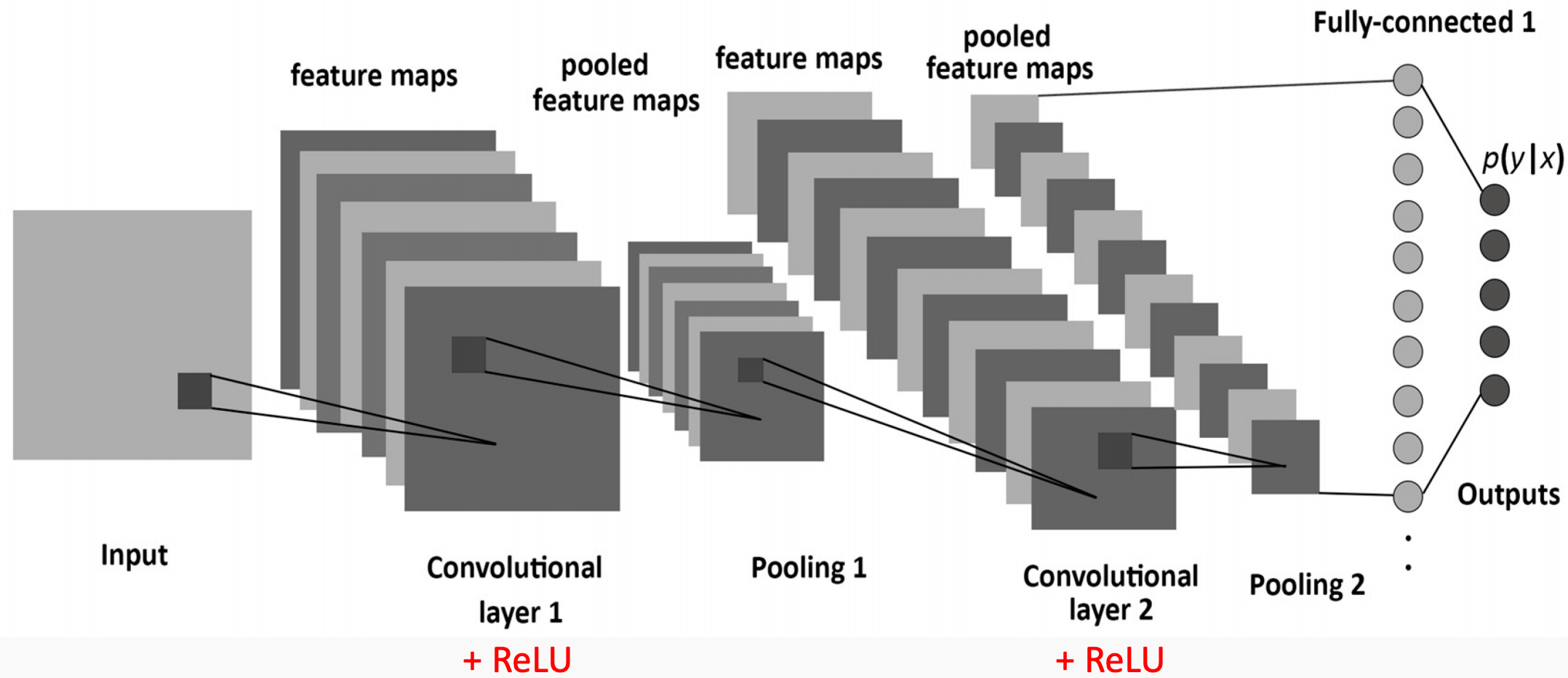
NOTE: Image Credits: Simple Introduction to Convolutional Neural Networks blog post.
The earlier layers in a CNN learn to understand lower level filters such as edges, corners. The latter layers will learn to detect more higher level features. In a network meant for classifying human faces, the latter layers will learn to detect features such as eyes, hands, nose etc.
For those interested in visualizing the output of individual layers in a CNN, this paper by Zeiler and Fergus makes for a fascinating read.
Some sample images from their paper are presented here:


NOTE: Image Credits: 3 part CNN series here
For a intro on different CNN architectures, click here and here